📚 数据冷热分离:用“断舍离”思维优化你的存储系统
如果说程序员是数字世界的“收纳师”,那么冷热分离就是我们的“断舍离”大法:把高频使用的数据放在手边,低频数据收进阁楼,既省空间又提效率。
但别急着关页面!这篇文章绝对不只有理论,我会结合真实踩坑案例、技术选型心路,甚至用“冰箱收纳”的比喻帮你彻底搞懂它!
🌟 冷热分离的本质:一场“资源再分配”的革命
❓ 为什么需要冷热分离?
想象一下:你的衣柜里堆满了衣服,但每天穿的其实就那几件。剩下的旧衣服既占空间,找起来还费劲。数据库也一样!80%的请求可能只访问20%的数据,剩下的大量“旧数据”却消耗着昂贵的存储资源(比如SSD)。
冷热分离的核心逻辑就是:让高频数据享受VIP通道,低频数据老老实实蹲仓库。
🔥 冷 vs 热:如何定义数据的“江湖地位”?
这里有两个经典判官:
-
时间判官(懒人首选)⏳
• 规则:一刀切,按时间划线。比如“1年内的订单是热数据,其他进冷库”。
• 适用场景:电商订单、日志监控等时间敏感型数据。
• 优点:实现简单,适合不想写复杂逻辑的“佛系团队”。
• 坑点:某些“老当益壮”的数据(比如经典文章)可能被误伤! -
访问频率判官(细节控最爱)📊
• 规则:谁活跃谁上位。比如“文章周访问量>100的保留在热库”。
• 适用场景:内容平台、社交媒体的动态数据。
• 优点:精准区分,避免“一刀切”误杀。
• 坑点:需埋点统计访问量,对代码有侵入性,还可能引发性能波动。
💡 我的实战建议:
• 新手村团队:先用时间维度试水,快速验证效果。
• 高玩团队:结合时间+访问频率,甚至引入机器学习预测数据热度(比如用历史访问规律预测未来热度)。
🛠 迁移冷数据:四种方案与我的“翻车”实录
迁移冷数据就像搬家,选错方案可能丢数据、拖垮性能,甚至半夜被运维夺命call!以下是我亲测过的四种方案:
-
方案一:业务层硬编码(慎用!)
• 逻辑:在代码里写死判断逻辑,比如“创建时间>1年?进冷库!”
• 翻车现场:曾在一个订单系统里用这种方式,结果某天运营要查历史订单,冷库数据没同步用户ID,直接查了个寂寞……
• 总结:耦合业务逻辑,后期维护噩梦,除非团队人少活急,否则别碰! -
方案二:定时任务搬运(推荐!)
• 工具:XXL-Job + Spring Batch
• 逻辑:每天凌晨扫描热库,把符合条件的数据“悄悄”搬进冷库。
• 优点:对业务代码零侵入,适合时间维度迁移。
• 避坑指南:
◦ 一定要加数据锁,避免迁移时被修改!
◦ 冷库表结构建议和热库一致,后续查询少踩坑。 -
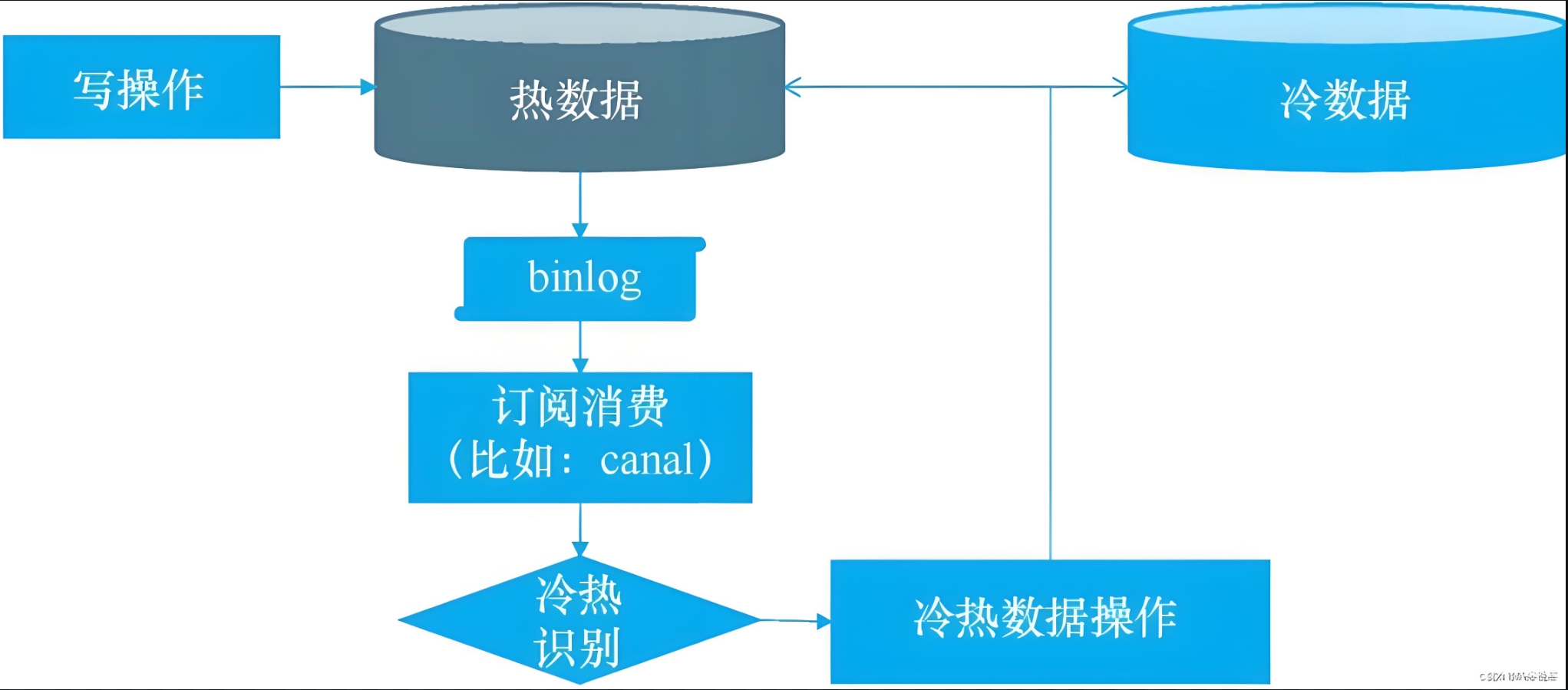
方案三:监听Binlog(高阶玩法)
• 工具:Canal + Kafka
• 逻辑:通过解析MySQL的Binlog日志,实时捕获数据变更,满足条件则触发迁移。
• 适用场景:需要近实时迁移的场景。
• 血泪教训:曾因没过滤“删除操作”,导致冷库数据被误删,从此牢记加白名单过滤! -
方案四:DBA手工搬运(救急专用)
• 场景:冷数据量极大,初次迁移时用脚本批量导。
• 友情提示:务必提前和DBA搞好关系,否则等你的是无数个“为什么要迁这张表灵魂质问”……
💽 冷库选型:从“小作坊”到“大厂”的进阶之路
🔧 中小厂方案:MySQL分库分表
• 为什么选它:团队技术栈统一,学习成本低。
• 骚操作技巧:
• 用ShardingSphere实现冷热路由:1年内订单走热库,1年前走冷库。
• 冷库直接用只读从库,省成本!
• 致命短板:跨库查询复杂,统计报表得合并冷热数据,JOIN到怀疑人生。
🚀 大厂方案:HBase/TiDB
• HBase实战心得:
• 适合海量冷数据存储,但别用它做复杂查询!
• RowKey设计是灵魂,比如用“用户ID+时间倒序”,避免热点问题。
• TiDB真香警告:
• 原生支持冷热分离,SSD存热数据,HDD存冷数据,运维成本直降50%。
• 但价格劝退!适合老板不差钱的团队(比如某宇宙厂)。
📈 冷热分离的收益与代价
🎯 收益:
• 性能提升:热数据体积缩小,索引更高效,查询速度肉眼可见提升。
• 成本直降:某项目迁移后,SSD存储费用从每月3万降到8千!
• 运维友好:冷数据备份周期可拉长,不用天天全量备份。
⚡️ 代价:
• 开发成本:至少增加20%的代码量(迁移脚本+数据一致性校验)。
• 数据一致性风险:迁移过程中若出现网络抖动,可能导致数据丢失。
• 统计复杂度:跨库查询需用Flink等工具做数据聚合,架构复杂度飙升。
🌈 写给技术人的思考
冷热分离不是银弹,而是一种平衡的艺术。
• 如果你追求极致性能,可以像某电商大厂那样,把热数据缓存到Redis,冷数据扔进HBase。
• 如果你预算有限,不妨先用MySQL冷热分库,搭配Elasticsearch做统计查询。
总结:技术方案没有对错,只有合适与否。冷热分离的终点不是技术,而是理解业务的数据生命周期——就像收纳衣服,你得先清楚哪些要留、哪些要扔,才能选出最合适的衣柜。

