高可用系统设计完全指南:从理论到实战
引言:为什么高可用系统是技术人的必修课?
在互联网服务中,“高可用” 是系统设计的生死线。一个经典的案例是2017年某知名电商平台在“双11”期间因数据库雪崩导致服务中断30分钟,直接损失超亿元。这样的教训告诉我们:高可用不是可选项,而是必选项。本文将从设计原则、核心策略、实战工具到避坑指南,为你构建一个完整的高可用知识体系。
一、高可用系统的核心逻辑
1.1 什么是高可用?——数字背后的意义
• 定义:系统在 99.9%~99.999% 的时间可正常服务(即“3个9”到“5个9”)。
• 可用性计算:可用性 = (总时间 - 故障时间)/总时间 × 100%
• 不同等级的影响:
| 可用性等级 | 年故障时间 | 适用场景 |
|————|—————|————————|
| 99.9% | 8.76小时 | 普通企业应用 |
| 99.99% | 52.56分钟 | 金融交易系统 |
| 99.999% | 5.26分钟 | 电信、航空控制系统 |
1.2 高可用的四大核心原则
- 冗余设计:无单点,多副本(如Redis Cluster、MySQL主从)
- 快速故障转移:秒级切换(如Keepalived VIP漂移)
- 弹性伸缩:自动扩容应对流量洪峰(如Kubernetes HPA)
- 防御性编程:预判并隔离故障(如熔断、降级)
二、高可用架构的七大实战策略
2.1 冗余与集群:让“单点”成为历史
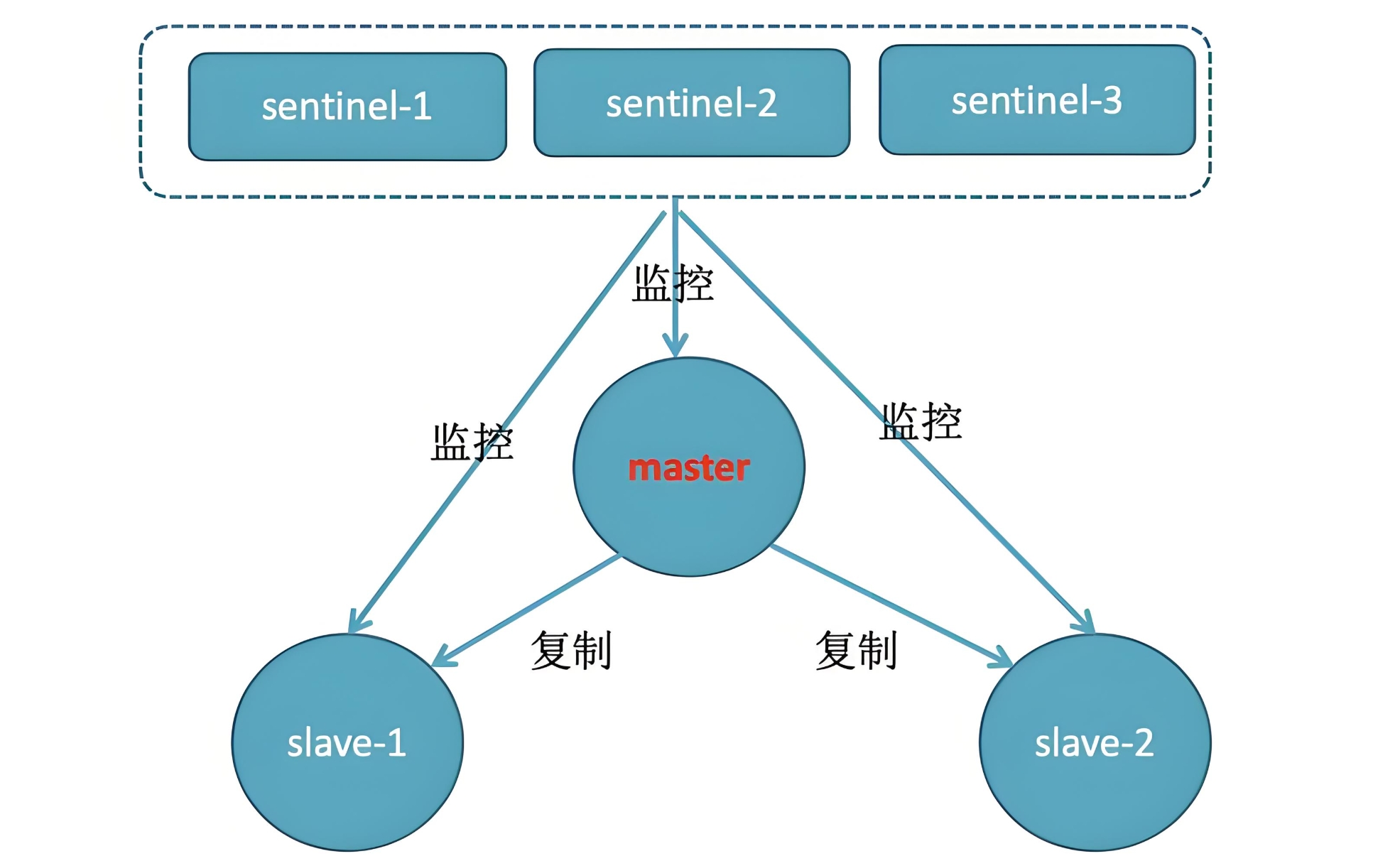
• Redis高可用方案对比:
| 方案 | 原理 | 优点 | 缺点 |
|---|---|---|---|
| 主从复制 | 一主多从,数据异步复制 | 简单易用 | 主节点故障需手动切换 |
| 哨兵模式 | 哨兵监控自动故障转移 | 自动化切换 | 写操作受限 |
| Cluster集群 | 数据分片,多主多从 | 支持水平扩展 | 配置复杂 |
• 数据库高可用: • MySQL MHA:30秒内完成主从切换 • TiDB:分布式NewSQL,自动分片+多副本
2.2 流量控制与熔断:守住最后一道防线
• Sentinel vs Hystrix:
// Alibaba Sentinel 限流规则配置示例
FlowRule rule = new FlowRule();
rule.setResource("orderService");
rule.setGrade(RuleConstant.FLOW_GRADE_QPS);
rule.setCount(1000); // 阈值1000 QPS
FlowRuleManager.loadRules(Collections.singletonList(rule));
• 熔断策略: ◦ 慢调用比例:响应时间>1s的请求占比超过50%时熔断 ◦ 异常比例:错误率超过60%时触发
2.3 超时与重试:避免“雪崩”的利器
• 黄金参数建议:
| 场景 | 超时时间 | 重试次数 | 退避策略 |
|---|---|---|---|
| 内部微服务调用 | 200ms~1s | 1~2次 | 固定间隔 |
| 第三方API调用 | 2s~5s | 0~1次 | 指数退避(Exponential Backoff) |
| 数据库查询 | 100ms~500ms | 不重试 | - |
2.4 异步化与消息队列:削峰填谷的终极武器
• Kafka实战案例:
# 创建Topic(3副本,6分区)
bin/kafka-topics.sh --create --topic order-events \
--bootstrap-server localhost:9092 \
--partitions 6 --replication-factor 3
• 异步处理流程:
用户请求 → API网关 → 写入Kafka → 消费者处理 → 数据库 ↑ | | 响应完成 异步通知 重试死信队列
2.5 缓存设计:四两拨千斤的加速器
• 多级缓存架构:
┌─────────┐ ┌──────────┐ ┌─────────┐
│ 客户端 │───→──│ CDN缓存 │───→──│ 本地缓存 │
└─────────┘ └──────────┘ └─────────┘
↓
┌──────────┐
│ Redis集群│
└──────────┘
• 缓存穿透解决方案: ◦ 布隆过滤器:拦截无效请求 ◦ 空值缓存:缓存NULL值(设置短TTL)
2.6 灰度发布与回滚:安全上线的双保险
• Kubernetes滚动更新策略:
apiVersion: apps/v1
kind: Deployment
spec:
strategy:
rollingUpdate:
maxSurge: 25% # 最大临时副本数
maxUnavailable: 25% # 最大不可用比例
type: RollingUpdate
2.7 监控与告警:系统的“听诊器”
• Prometheus + Grafana监控体系:
# 计算服务错误率
100 * sum(rate(http_requests_total{status=~"5.."}[5m]))
/ sum(rate(http_requests_total[5m]))
• 关键监控指标: ◦ RED指标:请求率(Rate)、错误率(Errors)、耗时(Duration) ◦ USE指标:使用率(Utilization)、饱和度(Saturation)、错误数(Errors)
三、从代码到运维:全链路高可用保障
3.1 代码质量:高可用的第一道防线
• 内存泄漏检测实战:
# 使用Arthas排查OOM
$ ./arthas-boot.jar
[arthas@12345]$ jvm
[arthas@12345]$ heapdump /tmp/heap.hprof # 导出堆快照
• 代码规范检查:
◦ SonarQube配置示例:
xml <!-- 自定义规则:禁止System.out --> <rule> <key>PrintStackTrace</key> <name>禁止直接打印堆栈</name> <priority>CRITICAL</priority> <configKey>common-java:PrintStackTrace</configKey> </rule>
3.2 混沌工程:主动制造故障的训练
• Chaos Mesh实验:
apiVersion: chaos-mesh.org/v1alpha1
kind: NetworkChaos
metadata:
name: simulate-network-latency
spec:
action: delay
mode: one
selector:
namespaces: ["production"]
delay:
latency: "500ms"
correlation: "100"
duration: "300s"
四、高可用设计的常见误区与避坑指南
4.1 误区一:过度追求“五个9”
• 成本陷阱:从99.99%到99.999%可能需要10倍投入 • 适用性原则:电商订单系统需99.99%,内部CMS系统99.9%即可
4.2 误区二:集群=高可用?
• 隐藏风险:
• 脑裂问题(ZooKeeper需配置quorum)
• 伪多活(未做单元化拆分)
4.3 误区三:忽视“幂等性设计”
• 重复请求导致资损案例: • 支付接口未做幂等 → 用户双击生成两笔订单 • 解决方案:Token机制或数据库唯一索引
结语:高可用是一场永不停歇的修行
高可用不是一次性的架构设计,而是需要持续优化的过程。建议每季度进行一次故障演练,每年做一次全链路压测。记住:“没有经过真实流量考验的高可用设计都是纸上谈兵”。
延伸阅读推荐: • 书籍:《Site Reliability Engineering》 • 工具:Chaos Engineering Principles(混沌工程原则) • 开源项目:Envoy(服务网格)、Vitess(数据库分片)

